
First, a recap of what we covered in the first two posts (here and here):
- If something is private, that means you’re free from consequences from external actors like peers, corporations and the government. Anonymity is closely related, with the crucial difference being that only your identity is hidden, but your information is not. In healthcare, we generally work with anonymous, or de-identified, data.
- A dataset’s value rises with more variables (dimensionality), but so do the privacy risks. This is because enriching datasets increases the potential to triangulate backwards to people’s identities (AKA re-identification), as when we linked new data sources to discover who left the mysterious footprint. For example, if you had access to both patients’ clinical and location data, you could theoretically re-identify patients based on when they visited the hospital and the dates of their clinical records. Plus, just like bleeding into crowds, it gets harder to be anonymous when there are fewer similar people, making de-identification difficult or impossible with small datasets or rare diseases.
- Privacy regulations like HIPAA an d GDPR protect healthcare privacy by stipulating the what, how and whom of data use to solve the privacy vs. utility tradeoff — but they only apply to real data (i.e., data points representing actual people), not to synthetic data.
That brings us back to how synthetic data protects privacy. Recall that synthetic data is realistic — but not real — data that mimics real data’s statistical properties without containing a single real person’s information. Syntegra creates synthetic data using a revolutionary application of a transformative machine learning approach, learning the complex relationships in the collective clinical stories of real patients, and then retelling the same narratives with “fake” characters. By breaking this one-to-one relationship between a datapoint and a person, synthetic data makes it way harder (i.e., impossible) to figure out anyone’s private information. Even synthetic versions of linked datasets with very high dimensions and small cohorts of rare diseases cannot be re-identified.
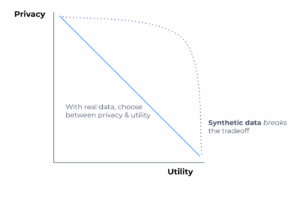
Reminder of the privacy vs. utility tradeoff for real and synthetic data. Note how synthetic data enables both higher privacy and utility simultaneously.
That sounds great, but how do you really know that synthetic data is protecting real peoples’ privacy? What if something went wrong and the synthetic data engine just copied and pasted the real data over into the “synthetic” dataset?
Syntegra tackled this question from the start by creating a set of privacy metrics, which we further verified in partnership with Mirador Analytics, one of the leaders in the HIPAA compliance space. By looking at the privacy of synthetic data in the same terms as real data privacy (disclosure risk), we created the first quantifiable and easily comparable metrics for validating that synthetic data does, in fact, fully safeguard privacy. And guess what? The risks we’ve found are at least ten times lower than de-identification — but, more often, they’re well over 1000 times lower. Combining this level of protection with an unprecedented level of fidelity and realism opens up new use cases that can change healthcare for us all — like offering free and open patient-level data for the first time ever or launching an API to make accessing healthcare data that much easier and faster.
For years, people have worried about the combined potential of big data and AI/ML to erode privacy — often for very good reasons — and concerns over the surveillance economy are growing. Privacy matters everywhere and particularly in healthcare, but how can we balance these concerns with the competing goal of improving health for real people?
The answer: synthetic data. Instead of sharing individual data, we can share data that represents all of us without revealing any of our information. More privacy means better access and more use of data, leading towards more innovations to benefit us all, but particularly for groups who are poorly served by the current de-identification system, such as rare disease patients whose data cannot be reliably de-identified. Stronger privacy protections can also improve trust in the healthcare system, which is vital for gathering crucial information on understudied groups and addressing care gaps to build a more equitable system. By protecting privacy as never before, synthetic data can enable a more innovative and fairer future. That future starts today — check out our new Synthetic Data API and get innovating today!